ORC Files
ORC 文件格式
Version
在 Hive 版本0.11.0中引入。
- Optimized Row Columnar *(ORC)文件格式提供了一种高效的方式来存储 Hive 数据。它旨在克服其他 Hive 文件格式的限制。当 Hive 读取,写入和处理数据时,使用 ORC 文件可以提高性能。
与 RCFile 格式相比,ORC 文件格式具有许多优点,例如:
一个文件作为每个任务的输出,从而减轻了 NameNode 的负担
Hive 类型支持,包括日期时间,十进制和复杂类型(结构,列表,Map 和联合)
存储在文件中的轻量级索引
跳过不通过谓词过滤的行组
- 寻求给定的行
基于数据类型的块模式压缩
整数列的游程编码
- 字符串列的字典编码
使用单独的 RecordReaders 并发读取同一文件
无需扫描标记即可分割文件的功能
限制读取或写入所需的内存量
使用协议缓冲区存储的元数据,允许添加和删除字段
File Structure
ORC 文件包含称为 stripes 的行数据组,以及 file footer **中的辅助信息。在文件末尾,一个“后记”包含压缩参数和压缩后的页脚大小。
默认的条带大小为 250 MB。大条带大小可实现从 HDFS 进行大而有效的读取。
文件页脚包含文件中的条带列表,每个条带的行数以及每一列的数据类型。它还包含列级聚合计数,最小,最大和总和。
下图说明了 ORC 文件结构:
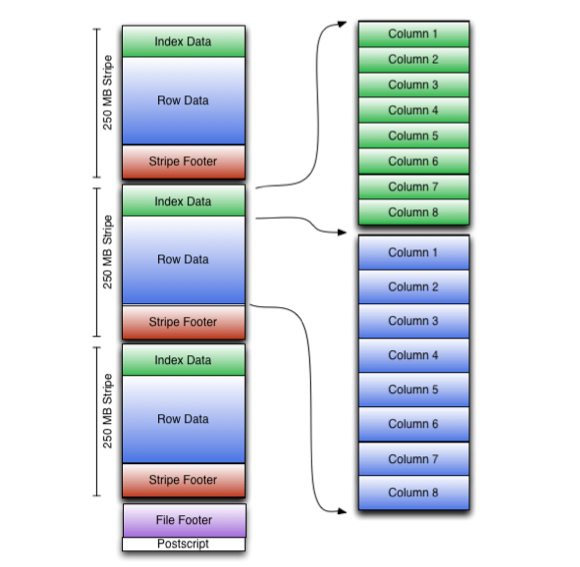
Stripe Structure
如图所示,ORC 文件中的每个条带均包含索引数据,行数据和条带脚注。
“条纹页脚”包含流位置的目录。 行数据 用于表扫描。
索引数据 包括每一列的最小值和最大值以及每一列中的行位置。 (还可以包括位字段或 Bloom 过滤器.)行索引条目提供偏移量,这些偏移量使能够在压缩块内寻找正确的压缩块和字节。请注意,ORC 索引仅用于选择条纹和行组,而不用于回答查询。
尽管条带尺寸较大,但具有相对频繁的行索引条目可以在条带内跳过行以快速读取。默认情况下,每 10,000 行可以跳过。
通过基于过滤谓词跳过大行集的功能,您可以在其辅助键上对表进行排序,从而大大减少了执行时间。例如,如果主分区是 Transaction 日期,则可以按状态,邮政编码和姓氏对表进行排序。然后在一种状态下查找记录将跳过所有其他状态的记录。
ORC specification中提供了格式的完整说明。
HiveQL Syntax
在表(或分区)级别指定文件格式。您可以使用以下 HiveQL 语句指定 ORC 文件格式:
CREATE TABLE ... STORED AS ORCALTER TABLE ... [PARTITION partition_spec] SET FILEFORMAT ORCSET hive.default.fileformat=Orc
这些参数都放置在 TBLPROPERTIES 中(请参见Create Table)。他们是:
| Key | Default | Notes |
|---|---|---|
| orc.compress | ZLIB | 高级压缩(NONE,ZLIB 和 SNAPPY 之一) |
| orc.compress.size | 262,144 | 每个压缩块中的字节数 |
| orc.stripe.size | 67,108,864 | 每个条带中的字节数 |
| orc.row.index.stride | 10,000 | 索引条目之间的行数(必须> = 1000) |
| orc.create.index | true | 是否创建行索引 |
| orc.bloom.filter.columns | "" | 逗号分隔的列名称列表,应为其创建 bloom 筛选器 |
| orc.bloom.filter.fpp | 0.05 | 布隆过滤器的假正概率(必须> 0.0 和<1.0) |
例如,创建不压缩的 ORC 存储表:
create table Addresses (
name string,
street string,
city string,
state string,
zip int
) stored as orc tblproperties ("orc.compress"="NONE");
Version 0.14.0+: CONCATENATE
ALTER TABLE table_name [PARTITION partition_spec] CONCATENATE可用于将较小的 ORC 文件合并为较大的文件(从Hive 0.14.0开始)。合并发生在条带级别,这避免了对数据进行解压缩和解码。
序列化和压缩
ORC 文件中列数据的序列化取决于数据类型是整数还是字符串。
整数列序列化
整数列在两个流中序列化。
-
- present *位流:值是否非空?
数据流:整数流
整数数据的序列化利用了数字的公共分布:
整数使用可变宽度编码进行编码,对于小整数,该可变宽度编码具有较少的字节。
重复的值是游程长度编码的。
游程长度编码范围内(-128 到 127)范围内恒定的值。
“可变宽度编码”基于 Google 的协议缓冲区,并使用高位表示该字节是否不是最后一个字节,而低 7 位则用于编码数据。为了对负数进行编码,使用曲折编码,其中 0,-1、1,-2 和 2 分别 Map 为 0、1、2、3、4 和 5.
每组数字的 encodings 如下:
如果第一个字节(b0)为负:
-b0 可变长度整数。
如果第一个字节(b0)为正:
它代表 b0 3 个重复的整数
在每个重复之间添加第二个字节(-128 至 127)
1 可变长度整数。
在*游程长度编码中,*第一个字节指定游程长度以及值是 Literals 还是重复项。重复项可以从-128 到 128 步进。游程长度编码使用 protobuf 样式的可变长度整数。
字符串列序列化
字符串列的序列化使用字典来形成唯一的列值。对字典进行排序可加快谓词过滤速度并提高压缩率。
字符串列在四个流中序列化。
-
- present *位流:值是否非空?
字典数据:字符串的字节
字典长度:每个条目的长度
行数据:行值
字典长度和行值都是整数的游程长度编码流。
Compression
使用编解码器压缩流,编解码器被指定为该表中所有流的表属性。为了优化内存使用,在生成每个块时,将逐步进行压缩。压缩块可以跳过,而无需首先将其解压缩以进行扫描。流中的位置由块的起始位置和块中的偏移量表示。
编解码器可以是 Snappy,Zlib 或* none *。
ORC 文件转储 Util
ORC 文件转储 Util 分析 ORC 文件。要调用它,请使用以下命令:
// Hive version 0.11 through 0.14:
hive --orcfiledump <location-of-orc-file>
// Hive version 1.1.0 and later:
hive --orcfiledump [-d] [--rowindex <col_ids>] <location-of-orc-file>
// Hive version 1.2.0 and later:
hive --orcfiledump [-d] [-t] [--rowindex <col_ids>] <location-of-orc-file>
// Hive version 1.3.0 and later:
hive --orcfiledump [-j] [-p] [-d] [-t] [--rowindex <col_ids>] [--recover] [--skip-dump]
[--backup-path <new-path>] <location-of-orc-file-or-directory>
在命令中指定-d将导致它转储 ORC 文件数据而不是元数据(配置单元1.1.0及更高版本)。
用逗号分隔的列 ID 列表指定--rowindex会导致它为指定的列打印row indexes,其中 0 是包含所有列的顶级结构,而 1 是第一个列 ID(Hive 1.1.0及更高版本)。
在命令中指定-t将打印编写者的时区 ID。
在命令中指定-j将以 JSON 格式打印 ORC 文件元数据。要漂亮地打印 JSON 元数据,请在命令中添加-p。
在命令中指定--recover将恢复由 Hive 流式传输生成的损坏的 ORC 文件。
指定--skip-dump和--recover一起执行恢复操作时不会转储元数据。
使用* new-path *指定--backup-path将使恢复工具将损坏的文件移动到指定的备份路径(默认值:/ tmp)。
*<location-of-orc-file> *是 ORC 文件的 URI。
*<location-of-orc-file-or-directory> *是 ORC 文件或目录的 URI。从Hive 1.3.0开始,此 URI 可以是包含 ORC 文件的目录。
ORC 配置参数
ORC 配置参数在配置单元配置属性– ORC 文件格式中描述。
ORC 格式规范
ORC 规范已移至ORC project。